Making Haiti HHA More Cloud Native
Introduction
hospital management system currently in development for Hope Health Action (HHA) is meant to help the hospital staff at Hospital Convention Baptiste d’Haiti (HCBH) in Haiti simplify their paperwork and facilitate decision-making with data-driven insights. The platform utilizes the MERN stack (MongoDB, Express, React, Node.js) with a monolithic architecture. It is hosted inside a Virtual Private Server (VPS) or Virtual Machine (VM) within SFU’s server.
The challenges developers encounter while developing and maintaining the HHA platform include restricted access to infrastructure resources, a vulnerability-prone architectural design, and insufficient backup systems. These issues collectively hinder effective development, increase the risk of downtime and data loss, and make it challenging to ensure a reliable hospital platform for HHA. Enabling developers more access to the infrastructure, strengthening architectural resilience, and implementing failovers are critical steps to address these vulnerabilities and improve overall platform stability.
This brings us to the concept of Cloud Native Applications, often misunderstood as merely referring to applications built on the cloud when it encompasses much more(Gannon, Barga, and Sundaresan 2017). In a nutshell, cloud-native applications are built and designed for the cloud and take advantage of the cloud computing model to be more resilient, manageable, and observable(Foundation n.d.).
This paper explores how HHA can benefit from a cloud-native application architecture on their Haiti hospital platform. It will show how, by being more cloud-native, the hospital platform can be more resilient, maintainable, and agile to develop.
Principal of Cloud Native Applications
The Cloud Native Computing Foundation is an organization that advocates for cloud-native adoption globally. Here is their official definition of cloud-native:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil. (Foundation n.d.)
The first sentence describes how cloud-native technologies allow organizations to build scalable applications in any environment, whether it’s public cloud (third-party cloud providers like AWS or Azure), private cloud (on-premise infrastructure for a single organization), or hybrid cloud (a combination of public and private cloud). It follows with a list of technologies and concepts that showcase the cloud-native approach to application development and deployment.
- Microservices: A small, independent set of services that works together to perform a complete application. Each microservice is responsible for a small, specific task or feature. They are independent of each other, meaning if one fails, the rest are not affected. Microservices work with each other through a standard communication protocol. They usually have a separate database and are developed independently from each other(“What Is Cloud Native? - Cloud Native Applications Explained - AWS” n.d.; robvet 2023).
- Containers: A container packs the source code and all the necessary dependencies into a single format. By containerizing, it enables more portability and standardization across environments. There are no more excuses of “it doesn’t work on my computer.”(“What Is Cloud Native? - Cloud Native Applications Explained - AWS” n.d.; robvet 2023)
- Service Meshes: The software layer that manages communication between microservices within a cloud environment(“What Is Cloud Native? - Cloud Native Applications Explained - AWS” n.d.).
- Immutable Infrastructure: A server hosting an application does not get repaired, updated, or modified. Instead, if an application requires more processing power, a new server with a more powerful CPU gets provisioned, and the application gets moved there, while the old server gets destroyed. All this is usually done through automation(“What Is Cloud Native? - Cloud Native Applications Explained - AWS” n.d.; robvet 2023).
- Declarative APIs: The APIs enable engineers to define the desired state of the infrastructure rather than having to list the steps required to achieve the desired state (the imperative way)(“What Is Cloud Native? - Cloud Native Applications Explained - AWS” n.d.). This minimizes complexity and reduces errors.
- Automation: One of the core DevOps principles is automation. Through automation, we minimized manual tasks that slow teams down or allow human errors. This is significantly essential when a project grows in size and complexity(“What Is DevOps? GitLab” n.d.).
Therefore, cloud-native applications are:
- Loosely Coupled: Small, individual components of an application are developed independently. Therefore, a change or outage in one component will not affect others(“Cloud Native Glossary” n.d.).
- Scalable: The application should also scale well with large numbers of concurrent users. It should be able to scale horizontally (adding nodes) or vertically (increasing resources) quickly(“Cloud Native Glossary” n.d.).
- Resilient: The application assumes that the cloud resources or third-party services it depends on will fail; thus, it is prepared to deal with them to remain available during outages(Toffetti et al. 2017).
- Manageable: The application and the infrastructure should be easy to manage and maintain.
- Observable: A system should be able to generate actionable insights. It enables users to understand a system’s state from the system’s output and take action if necessary. It refers to a system’s logs, metrics, traces, or dependencies(“What Is Observability? IBM” 2024).
- Agile: This defines how fast a business can bring an idea to the market. An agile business will be able to respond to market conditions rapidly(robvet 2023).
Although specific features and technologies might seem excessive for HHA’s operations in Haiti, both HHA and the developers can still reap the advantages of a cloud-native application. These benefits include enhanced resiliency, manageability, observability, and agility.
Overview of HHA Haiti
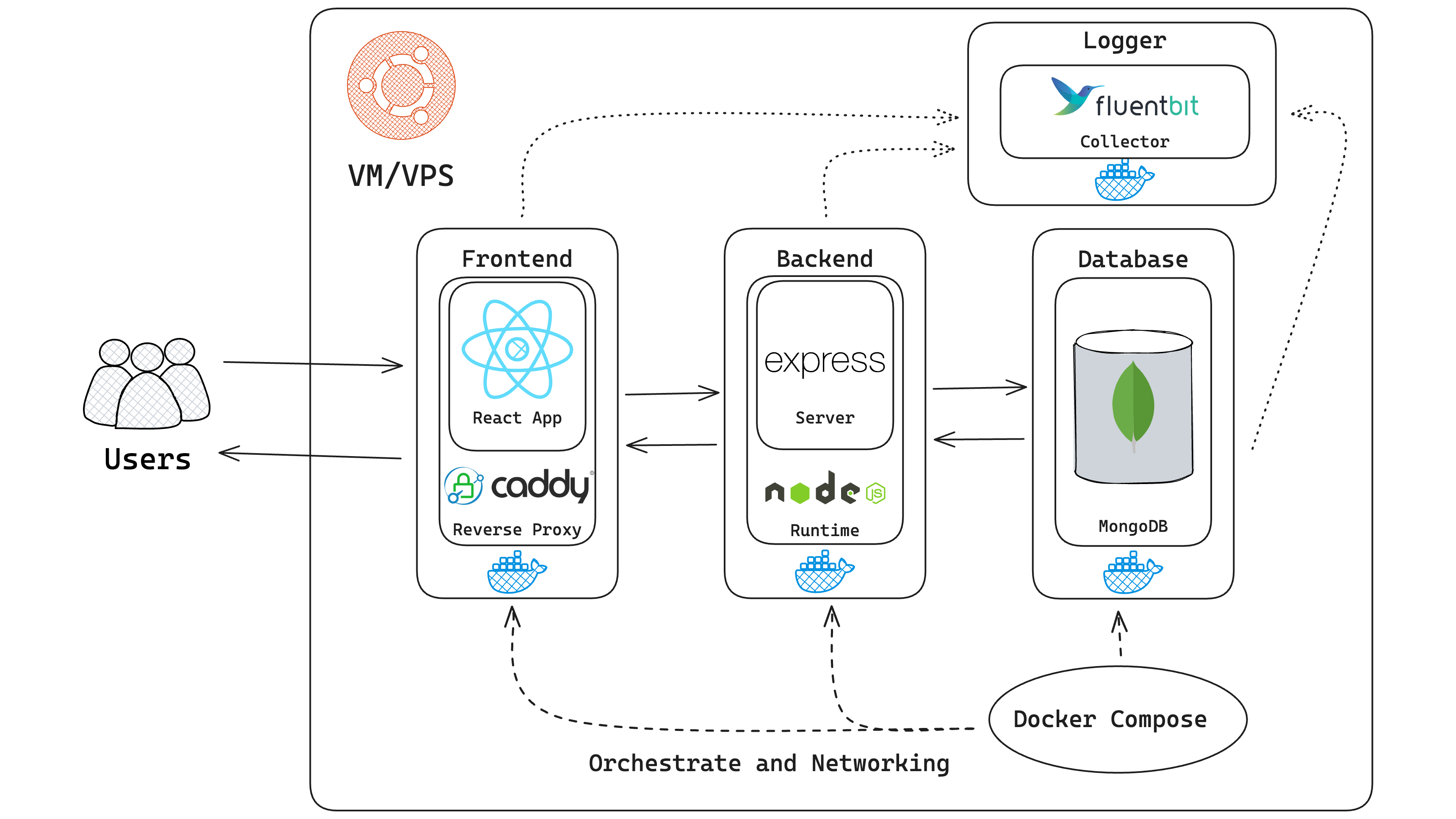
The current HHA Haiti hospital platform is a multi-container application that uses the MERN stack (MongoDB, Express, React, Node.js). It is divided into three layers, each running on a Docker container. We use docker-compose to orchestrate the different layers, seamlessly managing the services, networks, and volumes needed to run this application. The Docker containers run on top of a virtual machine (VM) within SFU’s server or a virtual private server (VPS) managed by HHA.
The project’s three layers exist within a single codebase. In addition, the project also has a common directory containing all the code that can be shared with the frontend and backend, such as report templates, custom question types, and many more. Each layer also hosts multiple features such as Reports, Employee of the Month (EoTM), Departments, Users, Equipment, Messages, etc. Therefore, it is evident that this project uses the monolithic architecture, where an application is developed as a single unit, is self-contained, and each component is tightly coupled with each other.
The decision to create a monolithic MERN stack application makes it easy for developers to prototype it quickly when it was first developed. For a small team that regularly changes and since the project has a small user base, it’s easier to maintain the application. The MERN stack empowers developers only to use a single common language, JavaScript. To be exact, we use TypeScript for the frontend and backend layers. However, TypeScript is a superset of JavaScript and will be compiled into JavaScript. Therefore, it is possible to share codebases between the frontend and backend(Pro MERN Stack n.d.). In our case, we shared the report templates and the question types. Since MongoDB stores JSON, data flows naturally from the client to the database, making it easier to debug and build (“MERN Stack Explained” n.d.).
Current Problems
As the project grows more complex, its existing architecture and infrastructure are increasingly strained.
Limited control of IT infrastructure
Currently, if a developer needs to modify the VM server—such as adding a new environment variable or troubleshooting Docker issues—this requires manual intervention by Dr. Brian. Consequently, it’s cumbersome and hampers productivity when doing DevOps tasks. Although the developers have been told to try any DevOps changes locally, some finer details might get overlooked, especially since we don’t have the exact VM image used on the server.
Vulnerability-prone Architecture
Recently, the development server experienced a shutdown due to high disk usage, necessitating a thorough cleanup. Although this occurred on a non-production server, the incident underscores the potential for a complete operational shutdown of the platform, particularly given that no additional instances were running, which could be alarming for a hospital environment. Therefore, our platform could be more highly available. The platform’s monolithic architecture means all features are affected when one feature becomes unavailable. In this setup, each service container is interdependent, linked via Docker Compose, and hosted on the same server. Consequently, a failure in any service layer can lead to the collapse of the entire platform. In addition, the current architecture does not prepare itself if the Docker host or hardware fails.
Insufficient Database Backup or Failover System
Configuring our MongoDB service in Docker Compose to always restart upon stopping and backing up the container volume to an AWS S3 Bucket is inadequate as a failover measure. Since we only have one MongoDB instance running, there needs to be more redundancy. Although we have shell scripts that routinely run a backup, they do not backup continuously, meaning there may be a period where data is lost. Then, our restore-from-backup script requires the user to run it manually rather than an automatic failover. Overall, the database needs a more robust backup system, especially since this is a hospital environment where lives may be at risk.
Long Build Times
The average time to build and deploy the platform via GitHub Actions after a pull request is merged into the main branch is approximately 15 minutes. This delay is primarily due to slow upload speeds experienced while uploading binaries post-build. Additionally, each build necessitates the reconstruction of binaries because even minor changes impact the entire layer, a consequence of the platform’s monolithic architecture. Consequently, even minor modifications result in significant delays.
Making the hospital platform Cloud-Native
Microservice Design
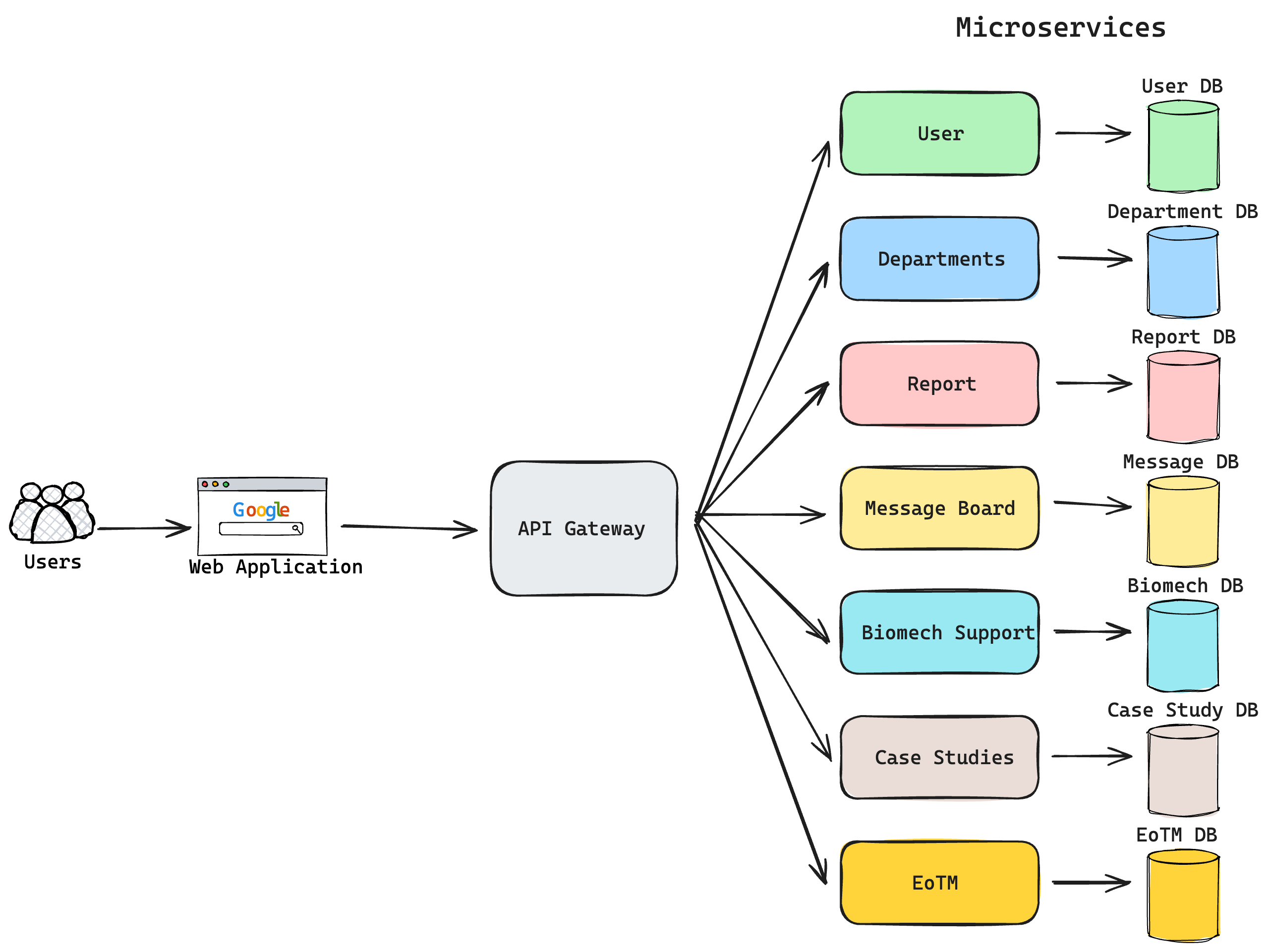
As we look to enhance the platform’s resiliency, manageability, and overall agility, I propose we begin transitioning towards a microservices architecture. This shift will allow us to break down the monolithic structure into smaller, independently deployable services, each meant for a feature. This modular approach improves fault isolation—ensuring that issues within one service do not impact others—and makes it easier for us to create redundancies without hosting an entire application elsewhere (Gannon, Barga, and Sundaresan 2017). Additionally, adopting microservices will facilitate more streamlined updates by reducing the build times needed, as only updated services need to be rebuilt. It is also more manageable as changes to a service do not affect the entire application(robvet 2023). This transformation can be strategically implemented in phases as you can break down the features into services individually. I suggest that implementation starts from straightforward functionalities. For example, I would begin with EoTM, Case Studies or Biomech support before working on more complex and critical functionalities such as Users or Reports.
Deploy to Kubernetes
Integrating the microservices architecture with a Kubernetes cluster deployment is highly recommended to enhance the platform’s resilience, manageability, and agility. Thanks to its sophisticated node scheduling and monitoring features, Kubernetes offers superior self-healing capabilities compared to Docker Compose and simplifies infrastructure management by abstracting it into a single, unified deployment platform. Developers can efficiently allocate specific resources for deployment using declarative configurations, eliminating system administrators’ need for direct intervention. This autonomy allows quicker deployment cycles, as developers can define the desired deployment state through a YAML file (Luksa 2017).
Given these advantages, I recommend setting up a Kubernetes cluster through a cloud provider like AWS EKS, Azure AKS, or Google GKE. The complexity of configuring our hardware for Kubernetes suggests that a cloud-based solution would be more feasible and practical, especially for HHA, who might have limited IT resources.
Additionally, I propose that the SFU School of Computing Science establish a Kubernetes cluster for educational purposes. This would provide a valuable, hands-on learning environment for students, particularly in courses like CMPT 415, enabling them to deploy and manage their applications effectively while maintaining security and minimizing risks. This initiative would enhance their technical skills and prepare them for real-world software development challenges.
GitOps The declarative nature of Kubernetes also introduces us to the concept of GitOps, where the state of the infrastructure and deployment is kept in a Git repository as a single source of truth, therefore enabling a more consistent infrastructure, enhanced visibility and audibility, enhanced security, while utilizing familiar tools and workflows, in this case, Git (Vinto and Bueno 2022). In conclusion, it improves manageability.
Managed Database
Despite the benefits of adopting a microservices architecture and utilizing Kubernetes, one significant challenge remains, the need to provision and maintain resources (Gannon, Barga, and Sundaresan 2017). This is critical when dealing with sensitive data such as patient records, where a highly resilient system with robust failover capabilities is essential. Given that HHA may have limited IT staff and resources, reducing the need for human intervention is crucial, especially concerning database management.
To address this, I strongly recommend fully managed services for our database needs. For instance, MongoDB Atlas would be more effective than self-hosting a MongoDB container. MongoDB Atlas offers comprehensive management services, including automatic maintenance, backups, and redundancy handling (“MongoDB Atlas Database Multi-Cloud Database Service” n.d.). This approach not only enhances the reliability and security of our database systems but also allows HHA to focus more on core functions by outsourcing the complex, resource-intensive tasks of database management. However, although MongoDB Atlas is a viable option, we should also look for other MongoDB database services. Some alternatives include Digital Ocean (“Managed MongoDB Hosting Starting at $15/Mo DigitalOcean” n.d.), Azure Cosmos DB, and AWS Document DB (The last two require MongoDB compatibility layer turned on) (“Other Document Database Compatibility — MongoDB Drivers” n.d.).
Conclusion
Migrating the hospital platform to a microservice architecture, deploying it to Kubernetes, and using a managed database on the cloud would make a more reliable, manageable platform and enable developers to be more agile in delivering features. To ensure a seamless transition, developers should migrate to a microservice architecture in phases, starting from the least critical feature. To reduce maintenance overhead for HHA and the developers, provisioning a managed Kubernetes cluster through a cloud provider is encouraged. As the database may contain sensitive patient data, it is suggested that we use a managed MongoDB service, like MongoDB Atlas, to outsource reliability, manageability, and backup concerns.
References
“Cloud Native Glossary.” n.d. Accessed April 24, 2024. https://glossary.cncf.io/.
Foundation, Cloud Native Computing. n.d. “Cloud Native Definition V.1.” Git {Repository}. GitHub. Accessed April 24, 2024. https://github.com/cncf/toc/blob/0cdf2c43a5a5db3ad87a71bd0fd937388ad6e4c5/DEFINITION.md.
Gannon, Dennis, Roger Barga, and Neel Sundaresan. 2017. “Cloud-Native Applications.” IEEE Cloud Computing 4 (5): 16–21. https://doi.org/10.1109/MCC.2017.4250939.
Luksa, Marko. 2017. Kubernetes in Action. Simon; Schuster.
“Managed MongoDB Hosting Starting at $15/Mo DigitalOcean.” n.d. Accessed April 24, 2024. https://www.digitalocean.com/products/managed-databases-mongodb.
“MERN Stack Explained.” n.d. MongoDB. Accessed April 24, 2024. https://www.mongodb.com/resources/languages/mern-stack.
“MongoDB Atlas Database Multi-Cloud Database Service.” n.d. MongoDB. Accessed April 24, 2024. https://www.mongodb.com/atlas/database.
“Other Document Database Compatibility — MongoDB Drivers.” n.d. Accessed April 24, 2024. https://www.mongodb.com/docs/drivers/other-document-dbs/.
Pro MERN Stack. n.d. Accessed April 24, 2024. https://link.springer.com/book/10.1007/978-1-4842-4391-6.
robvet. 2023. “What Is Cloud Native? - .NET.” https://learn.microsoft.com/en-us/dotnet/architecture/cloud-native/definition.
Toffetti, Giovanni, Sandro Brunner, Martin Blöchlinger, Josef Spillner, and Thomas Michael Bohnert. 2017. “Self-Managing Cloud-Native Applications: Design, Implementation, and Experience.” Future Generation Computer Systems 72 (July): 165–79. https://doi.org/10.1016/j.future.2016.09.002.
Vinto, Natale, and Alex Soto Bueno. 2022. GitOps Cookbook. "O’Reilly Media, Inc.".
“What Is Cloud Native? - Cloud Native Applications Explained - AWS.” n.d. Amazon Web Services, Inc. Accessed April 24, 2024. https://aws.amazon.com/what-is/cloud-native/.
“What Is DevOps? GitLab.” n.d. Accessed April 24, 2024. https://about.gitlab.com/topics/devops/.
“What Is Observability? IBM.” 2024. https://www.ibm.com/topics/observability.